

Recently (I'm talking about the last three or four months or so), I relied on restoring an older version from a backup, at least for some parts of the project. The project is, of course, ZPE Programming Environment. This is because the new features added unintentionally caused issues with previously added features. Much to my disappointment, this meant rolling back several versions of the code to mitigate the problems brought by the new changes.
My commit messages helped a lot here but were not perfect. The messages often describe fixes or new features being added but do not detail precisely how I do this. That's because the ZPE Programming Environment core is closed-source, and I do not want to share all the new things in full detail to everyone (particularly when it could affect security).
Take this commit:
Added a fix that seems to have fixed bug #35 ("Fix excess bracketed calls")
They are far more helpful because I can refer to the bug in more detail. This led to the ZPE Tracker, which is designed to identify and describe bugs and features brought to ZPE and allows commit messages, which could be done just before heading to work, to be much less detailed and just linked to the bug number.
Anyway, commit messages are designed for several reasons, but one of the main reasons is that if a program needs to roll back to a previous version, finding that version can be done much more straightforwardly. ZPE is multifaceted in that I record commit messages, update the changelog, and maintain a list of bugs and features on the Tracker.
In general, from working in the industry and working on my projects such as BalfBar, DASH etc, commit messages must be incredibly detailed. They are designed to ensure that other developers can pick up the code and figure out exactly what happened in the last commit and for team members to see exactly what a developer did on a project. Messages, therefore, must be incredibly clear.
The title, "I'm happiest when I'm in my IDE", isn't entirely accurate, but my IDE means a lot to me.
Thanks to a friend, my love was recently rekindled for IntelliJ IDEA again. I used it briefly while at university and loved it, but then I remembered that I had an edition that allowed me to use it as a student. Since I am no longer a student, I could not acquire that version and stuck with the Eclipse IDE for my Java programming, Visual Studio for C#, Visual Studio Code for Python and Atom/Pulsar for web development.
Atom and Pulsar are lovely editors with many features that I love. Visual Studio is the editor I have been using for the longest since the first language I learned, which I still actively use, was C#. Visual Studio Code has always been one of my favourite IDEs, but it lacks many of what other editors offer. Eclipse, however, is very dated, and whilst it does the job, it lacks a lot.
JetBrains IDEs, on the other hand, offer the best of everything. This is where the title of the post makes sense. I genuinely am happiest with the JetBrains suite of IDEs because the IDE I'm working with affects how I feel when writing code. And I say that because there are so many great things in them.
Take IntelliJ, for example. I put ZPE's code into IntelliJ, which has reshaped it. IntelliJ has shown me areas in which I can improve my code, for example, by replacing length == 0 with isEmpty(), or removing unnecessary assignments or variable initialisation when the variable gets initialised immediately after declaration.

My IDE means a lot to me, and I've heard the same from other programmers who also believe it affects your mental health whilst you are working. I decided just to do what I've been contemplating for a while and bought the JetBrains suite for the first time.
Whilst I'm not the biggest user of Bash, I do use it at least everyday for lots of jobs. I learned a lot from a friend but also from experimenting a lot whilst being an OS X user. In this post I'm going to discuss the main benefit of Bash for me.
The first notable benefit of Bash is automation. Since Bash is relatively easy to access and will not need compiled it's easy to automate certain things. One of the things I use Bash for is it's find command. This allows me to list all files which match a certain name. Using this command I can run an exec command on it and do things like move them or delete them.
But, you ask, I've got a Mac with a graphical interface so why do I not just search using the Finder search tool? This is very true but I'm not able to do that on my Raspberry Pi which is not connected to any display am I? No. What I do here is the second notable benefit of Bash - remote login.
Remote login is generally handled by SSH for me. This fantastic tool lets me manage my Raspberry Pi remotely from my Mac but it also gives me access to the server from which this website is being hosted on. Couple the two aforementioned features of Bash and I can manage my website server using my Mac remotely. Not only does this give me more access around the server but it gives me speed.
Say I want to delete 1,000 files which are in a directory of directories, I would need to recursively delete them. With FTP, I would request the deletion of the whole directory and my FTP client (FileZilla) would send a REMOVE command to the server. However, before it can do that it would need to go into each sub directory, recursively (meaning it would need to visit each sub directory of that sub directory too) and send a REMOVE command on each file inside of it and then on the empty directory itself. The FTP client needs to check each directory out for any files which it requests from the server each time. This is a long and cumbersome task. For me it takes no time though, because I know Bash.
Using Bash the deletion of remote files can be sped up considerably. Once I've SSH'ed into my server and I wish to remove a directory and it's contents it's fairly simple:
rm -r test_dir
In the above example I'm removing the test_dir directory and it's contents. Since Bash sends a single one line command to the server which the server then interprets and executes using its own Bash interpreter, the execution time for the above example is less than one second. This is an astronomical improvement over the FTP client.
So there you have it. My favourite reason for using Bash.
I will criticise Bash over one thing however, and I guess I think of myself as a bit of a snob when it comes to programming languages since I feel that a lot of languages have ugly syntax and I do not feel that Bash is any different. For example if statements do not use the normal < or > signs to represent their comparators. No, in Bash this is done with the -lt and -gt words. Then you've got the whole thing with variables where instantiating a variable does not require a $ but referencing one does.
This ugly syntax has often deterred me from using Bash to do something. My own ZPE aimed to fix a lot of this and has, just without the horrid syntax of Bash. It's worth a look if you want a simple scripting syntax and powerful language all in one.
Version 1.4.2HA is the current alpha version of the next ZPE and it's the biggest change to ZPE in the history of ZPE, a lot of code written in version 1.3.x has been replaced with much more efficient code, particularly with the evaluation of conditions and maths.
Real Math Mode was added in version 1.3.5.60 but it was always up for evaluation. The compiler side of it was written in a way that allowed the compiler to 'peek' at several symbols ahead of the current symbol in the traversal. Brackets were considered mathematical, so if a mathematical symbol wasn't found, ZPE would assume since seeing brackets that it was a mathematical expression. That meant that logical expressions were never considered on this expression.
Now in ZPE 1.4.3 (which I will hopefully release soon) mathematical and logical expressions are compiled to the singular "EXPRESSION" token and then, at runtime are evaluated to a mathematical expression or a logical expression based on the first token found.
E.g.
+
55 33
Would make the interpreter realise this is mathematical, not logical. With the following it would also realise that this is logical:
&&
true false
And this is because it sees an AND token (&&).
What about brackets though? Well, the interpreter will skip through brackets going right down to the base and do exactly the same with that. Easy.
This makes the compiler also more efficient and certainly more reliable.
I have just recently finished the compiler side and the interpreter side was easy enough to modify for the new system.
Much of what made ZPE the way it was back in the day has been replaced with a fresh system that does less work, has lead to much fewer traversals and makes far more sense. Logic is evaluated in the exact same way as mathematical expressions. By doing this, the system follows the orders of precedence where AND will always be evaluated before OR.
As a result of the change, the factorial problem as I know it as currently, has been fixed, so $z = (factorial($n + $r - 1)) / (factorial($r) * factorial($n - 1)) now works without the 0 + at the beginning of the first brackets.
This update also eliminated the need for the compiler to peek at the next bunch of symbols until it found a terminator or a mathematical or logical symbol.
Update 1.4.3 has since been released and trialled. I'd like to thank Merlin for pointing out a few bugs within the new LAMP interpreter.
Version 1.4.3 changes what was described above and assess the expressions in the compiler to mathematical or logical, thus removing this from the interpreter. The system still works the same.
Version 1.4.3 drops support for XOR in a statement since it was far too complicated to parse correctly, but it does re-add the xor command. A lot of what was done in the interpreter has been shifted to the compiler, allowing the compiler to compile more efficient programs and to reduce execution time on the interpreter side of things, which as a result means that while loops and for loops will interpret faster.
I'm hoping to make several more compiler-based improvements that will make small yet noticeable differences for the interpreter.
I genuinely believe that version 1.4.3 is the first version where the core is actually finished in both the interpreter and compiler.
Over the last few years, I've done a lot of work on building my own programming language and platform known collectively as ZPE.
Perhaps the most important lesson I have learned from this is how to make a program more efficient. I focus a lot on shifting things from the interpreter/runtime side to the compile-time side in ZPE, which has been a major focus of the latest version. However, there are some things that I cannot do very easily.
I recently started thinking about making one of my programs more efficient and how this would work in ZPE. Let's take a look at some code:
$l = range(1, 5000) //For x is less than the length of the list (i.e. 5000), increment by 1 for ($x = 0, $x < list_get_length($l), 1) print($x) end for
Notice how we check the size of the list at the top of the for? This means each iteration will need to call that function to find the size of the array. If a variable had been defined before the for loop and contained the length of the list, one could simply reference the variable, which in turn would be much faster than constantly asking the system to find the length of a 5,000 element array. Here is a sample of this in action.
$l = range(1, 5000) $len = list_get_length($l) //For x is less than the length of the list (i.e. 5000), increment by 1 for ($x = 0, $x < $len, 1) print($x) end for
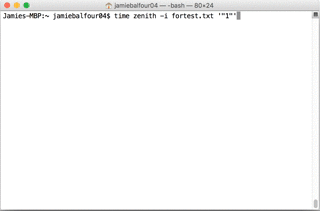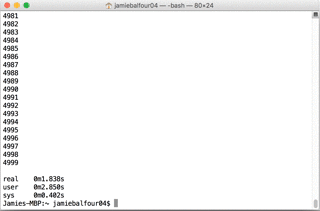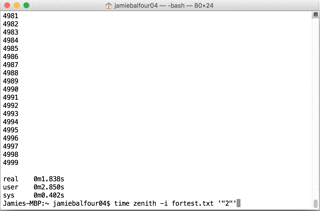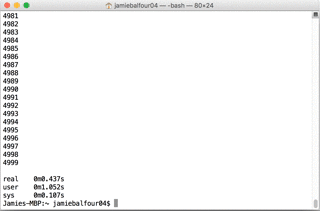
Times were measured using the Unix time command and were as follows:
For the first test:
real 0m1.821s
user 0m2.862s
sys 0m0.363s
And for the second test:
real 0m0.437s
user 0m1.051s
sys 0m0.099s
This is the first tip I have for you. This tip will also work in other languages such as JavaScript or Java or whatever.
In 2020
In 2020 when I was looking through my blog, I came across this post and thought I'd test it out again for a bit of fun. Interestingly, running both for loops is considerably faster than even the faster for loop example provided here. Compiler optimisations, runtime improvements and much more have made this much faster in ZPE 1.8.5. The version shown above is running on ZPE 1.4.2E, which is still available to download and compare.
Since I first used Python back in 2012, I've come a long way. It was never my intention for Python to become another of the languages I know since I feel that I know enough languages as it is. Still, naturally, one of my university courses had to disagree with this and stick it in.
So I learned Python, all in the space of about 24 hours because the Python I learned before has been completely changed (other than one or two small things like the def: and the stupid lack of braces).
I've really come to dislike Python as a language though, and I'm sure I'm not the only one.
I believe the Python syntax is the worst syntax I've ever seen.
I mean the lack of braces and semi-colons (;) means that there are no line terminators and no nice structures generated by braces or even as shown in ZL a for is opened by the word for optionally followed by a { and terminated by either an end for or a }
I like the way Python encourages indentation, but I hate this being an absolute requirement.
Python seems very ugly throughout; the use of the colon (:) before the body of a construct seems horrible. And the lack of the required brackets around a condition is even more horrid.
Another really awful discovery I made when messing about with Python is the fact that lambda functions can only be single-lined. I mean what? Even after 24 years of development (as old as I am!), this is still the case whereas in my 7-month-old ZL language lambda functions have no limit to their length. This is an absolute disgrace for any modern-day language as I see anonymous functions as one of the building blocks of ZL.
But perhaps the worst bit is the way that we declare things in Python. Since there is absolutely no need to specify a type variables need only be written as the name of the variable followed by an equal sign and then the value. Other weakly typed languages like PHP, JavaScript, my own ZL and so on have nicer ways of doing this like with PHP and ZL putting a $ sign in front of the name represents a variable. This makes it easier to distinguish variables. In JavaScript, variables are declared after a var keyword.
Since I started to write my own programming language, ZL, I have become more of a snob towards languages that are, in my eyes at least, ugly. Python is my absolute least favourite while PHP comes up number one for inconsistencies (although it is improving, and it is still a better solution in my eyes than any other server-side language).
Python swiftly moved to my least favourite language just this month.
I mean, a language is a language and if you like it that's great, and my opinion is just an opinion and all I'm saying here is how I dislike certain things about Python. I'm interested in your opinions on this too by the way.
Just yesterday I got myself an Xbox One (There may be a review on this coming soon). I tried out Internet Explorer on it, which I found out was Internet Explorer 10.
I also discovered that my PHP script to detect Internet Explorer 8 accepted Internet Explorer 10 as being an older version than Internet Explorer 8. This is a simple mistake to make but it's also incredibly easy to fix.
Here was what I had:
preg_match("/.* MSIE [1-8] .*/i", $userAgent)
And here is a working solution, to detect all browsers less than IE8:
preg_match("/.* MSIE [1-8].[0-9]?; .*/i", $userAgent)
And the reason for this happening is down to the fact this only checks the first number of the version, not the second, so IE10 would be recognised as IE1. I also put in, just for the sake of it, a check for a dot (.) and a check for a minor version number ([0-9]) and a semi-colon at the end. At the beginning and end of the regular expression match are any symbols.
Today, I was working on the next release of Painter Pro, codenamed Dundee which I am releasing as version 1.3 of the application, and is next in line after St Andrews and the current build known as Aberdeen. For the Dundee build, there are some major changes. As I started work of improving the speed of algorithms used in Painter Pro, I also started to look at other ways to improve the overall performance.
Whilst I was working away, improving speed, I was working on linking code to make it efficient. I noticed that whilst I was working on this, all of my classes linked together through one library, i.e. they were all dependant on this one class library. Three libraries make up a lot of the components of my software, namely Balfour's Business Class Library (a set of business tools, methods, controls and more), Balfour's Business File Extension Library (a set of file extensions for use in the business applications) and Balfour's Business Extension Class Library (a set of tools, methods, controls and more which build upon the BBCL and is loosely coupled to it).
The class library houses all of my file extensions and nothing more (BIF, WUX, DUX, RUX, QQS and more). This is why I did not want the library to contain this code. Instead of doing this, I decided to duplicate the code (which again is not a good idea). The file extension library should be independent of all of the other libraries, or at least of the extension library. If they are linked, none of them can compile, because the changes require the latest versions of each other.
Coupling like this should be avoided, not just so that the libraries work alone but so that at least one of the libraries can function without the other. It's a very important part of writing a good library of classes.
